728x90
Misclassification Rates Example Codes: guess, test data
포스트 난이도: HOO_Lead
# Example Codes
# Library
import numpy as np
import pandas as pd
from scipy.stats import norm, t
import matplotlib.pyplot as plt
def getClass1Prop(x,r):
x=np.array(x)
dist=np.zeros(len(x_train))
for i in range(len(x_train)):
dist[i] = np.linalg.norm(x-x_train[i])
dist_label_1 = dist[y_train==1]
dist_1r = dist_label_1[dist_label_1<=r]
if len(dist[dist<=r]):
return len(dist_1r)/len(dist[dist<=r])
else:
return np.nan
def computeMisValData(val_data, r):
x_val = val_data.iloc[:,1:3].to_numpy()
y_val = val_data['Y'].to_numpy()
y_pred = np.zeros(len(y_val))
for i in range(len(x_val)):
p = getClass1Prop(x_val[i],r)
y_pred[i] = 1 if p >= 0.5 else 0
mis_val = (len(y_val)-(y_pred==y_val).sum())/len(y_val)
return mis_val
# check data
df = pd.read_csv("SML.NN.data.csv")
print(df.head(10))
df.info()
# declare train, valid, test
data_train = df[df['set']=='train']
data_valid = df[df['set']== 'valid']
data_test = df[df['set']=='test']
x_train = data_train.iloc[:,1:3].to_numpy()
y_train = data_train['Y'].to_numpy()
x_val = data_valid.iloc[:,1:3].to_numpy()
y_val = data_valid['Y'].to_numpy()
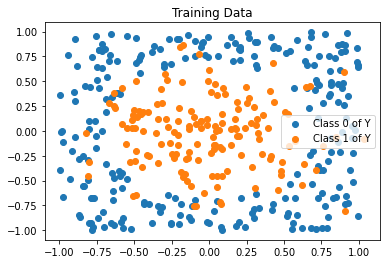
plt.figure()
plt.scatter(x_train[y_train==0][:,0], x_train[y_train==0][:,1],label = "Class 0 of Y")
plt.scatter(x_train[y_train==1][:,0],x_train[y_train==1][:,1],label="Class 1 of Y")
plt.legend()
plt.title('Training Data')
plt.show()
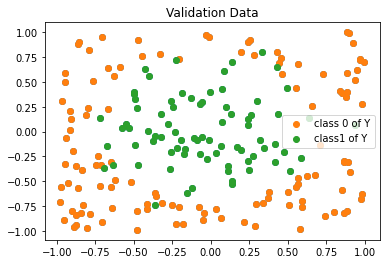
plt.figure()
plt.scatter(x_val[:,0], x_val[:,1])
plt.scatter(x_val[y_val==0][:,0],x_val[y_val==0][:,1],label="class 0 of Y")
plt.scatter(x_val[y_val==1][:,0],x_val[y_val==1][:,1], label="class1 of Y")
plt.legend()
plt.title('Validation Data')
plt.show()
# Compute the misclassification rate (refer to 1.2)
# define compute the misclassification rate
def computeMisRate(dt, r):
x_test = dt.iloc[:,1:3].to_numpy()
y_test = dt['Y'].to_numpy()
y_pred = np.zeros(len(y_test))
for i in range(len(x_test)):
p = getClass1Prop(x_test[i],r)
#proportion higher 0.5
y_pred[i] = 1 if p >= 0.5 else 0
misclassificationRate = (len(y_test)-(y_pred==y_test).sum())/len(y_test)
return misclassificationRate
r = np.arange(0.01,1.01,0.01)
mis_total=[]
for i in r:
mis_total.append(computeMisValData(data_valid, i))
plt.figure()
plt.plot(r,mis_total)
plt.xlabel('r')
plt.ylabel('Misclassification Rate')
plt.show()
rate=r[np.argmin(mis_total)]
print("Guess rate:")
guess = float(input())
print("Lowest misclassification rate is, ", guess ," in my guess by using the plot.")
misclassification = computeMisRate(data_test, rate)
misclassificationGuess = computeMisRate(data_test, guess)
print("r = ", rate , "Misclassification rate(test data): ", misclassification)
print("r = ", guess , "Misclassification rate(guess): " , misclassificationGuess)
if (misclassification > misclassificationGuess):
print("The rate is better than the guess rate.")
else:
print("Guess rate is better than the misclassification rate.")
print("posted by HOO.")# Results
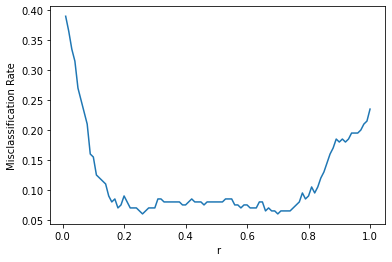
Guess rate:
0.23
Lowest misclassification rate is, 0.23 in my guess by using the plot.
r = 0.26 Misclassification rate(test data): 0.045
r = 0.23 Misclassification rate(guess): 0.05
Guess rate is better than the misclassification rate.GitHub - WhoisHOO/HOOAI: https://whoishoo.tistory.com/
https://whoishoo.tistory.com/. Contribute to WhoisHOO/HOOAI development by creating an account on GitHub.
github.com
728x90
'AI & Data > AI&ML Examples' 카테고리의 다른 글
| [AI / Computer Vision] YOLOv8 맛보기 후기 (0) | 2023.07.27 |
|---|---|
| [SML] Marginal PDF Example codes (0) | 2023.02.15 |
| [AI/ML Examples] Factorization criterion in action in the special case of the bivariate normal pdf (0) | 2023.02.06 |
| [AI/ML Examples] MLE with data from exponential distribution (0) | 2023.02.06 |
| [SML] Critical Thinkings of The Linear Regression (0) | 2023.01.30 |




댓글