커스텀 데이터셋으로 사물 분석하기 (Object Detection by Custom Dataset)
포스트 난이도: HOO_Senior
# 커스텀 데이터셋 (Custom Dataset)
이전 포스트에서 코코 데이터셋을 활용해서 간단한 Obejct detection을 해보았다. 코코 데이터셋은 욜로에서 제공하는 기본 데이터셋으로써 욜로를 학습하는 데에도 활용되었던 데이터셋에 해당된다. 예를 들자면 우리가 파이썬을 사용한다고 가정했을 때 별도의 모듈 설치 없이도 기본적으로 사용이 가능한 기능들이 있는 것처럼 욜로를 사용하는 데 있어서도 코코 데이터셋으로 학습된 라벨링의 경우에는 이미지 디텍팅이 바로 가능하다. 아래의 링크를 참고하면 해당 포스트를 살펴볼 수 있다.
https://whoishoo.tistory.com/630
[AI / Computer Vison / Object Detection] COCO Dataset으로 간단한 Object Detection 해보기
COCO dataset으로 간단한 object detection 해보기 포스트 난이도: HOO_Middle # COCO Dataset COCO는 Common objects in context의 줄임말로 YOLO와 같이 computer vision의 효율성 향상을 위해서 만들어진 오픈형 데이터셋이
whoishoo.tistory.com
하지만 실무에서 코코 데이터셋에 있는 라벨링 이미지만 사용할 수는 없는 법이기에 우리는 자체 데이터셋을 통해서 Object detection 뿐만 아니라 Computer vision 작업을 수행할 수 있다. 데이터 라벨링이 된 데이터셋을 가지고 있다면 해당 해당 데이터셋을 사용하면 되지만, 만약에 라벨링이 되어 있는 데이터셋이 없다면 라벨링을 한 뒤에 욜로 v8을 통해서 데이터 학습과 이미지 디텍팅이 가능하다. 너무나 귀찮은 라벨링 작업이지만 알게 모르게 점점 라벨링의 베테랑이 되어가고 있는 모습을 보면서 데이터 라벨러가 직업인가 싶기도 하다. 애증의 관계인 데이터 라벨링이다.
데이터 라벨링에 대해서 간략하게 설명하자면 (HOO_Senior니까 짧게 설명하겠습니다.) 마치가 우리가 글을 작성하기 전에 연필을 깎듯이 욜로를 사용해서 이미지 학습을 시키기 위한 준비단계라고 보면 된다. 사람이야 눈으로 보고 엄청난 프로세스를 단기간에 거쳐서 특정 사물을 인식하지만 현재의 데이터 기반 인공지능의 경우에는 이러한 프로세스가 자동으로 이루어지지 않기 때문에 라벨링이라는 작업을 통해서 이미지를 구분해주어야 한다. 마치 갓난아기에게 손으로 가리키면서 엄마가 누구이고 아빠가 누구인지 알려주는 거와 같다.
과거에 비해서 라벨링과 각 환경에 맞는 데이터셋으로 Export을 해주는 서비스를 제공하는 사이트가 많아졌기에 본인에 맞는 사이트를 찾아서 라벨링 작업을 해주면 된다. 많은 개발자들이 Roboflow을 사용하고 있는데, 글쓴이의 경우에는 이번 포스팅에서 활용한 라벨링 사이트는 CVAT이다. 참고로 한국에서도 학습 데이터셋을 제공하고자 라벨링이 된 데이터셋을 제공하고는 있으나, 아직은 데이터셋 양도 많지 않고 깔끔하게 정리가 부족한 거 같아서 아쉬웠다. 그래도 이런 노력을 하고 국민들에게 무료로 제공하는 데이터셋이 있다는 것 자체에 역시 대한민국이다!라는 생각이 든다. (사실 글쓴이는 국뽕 남이다.)
Roboflow: Give your software the power to see objects in images and video
With just a few dozen example images, you can train a working, state-of-the-art computer vision model in less than 24 hours.
roboflow.com
CVAT
Powerfull and efficient open source data annotation platform for computer vision datasets
www.cvat.ai
해양수산빅데이터 거래소
해양수산빅데이터 거래소
www.bigdata-sea.kr
# Codes
글쓴이가 이번에 사용한 이미지는 USDA에서 제공하는 Citurs canker 이미지를 활용하였다. canker는 바이러스의 한 종류인데 사실상 컴퓨터쟁이에게는 이런 게 중요하지 않을 테니, 그냥 바이러스의 한 종류이며 귤 종류의 겉면의 모양을 바꿔준다고 생각하면 된다. 농업과 관련된 구체적인 내용은 아래의 링크를 참고하면 된다.
HOOFARM
인공지능, 블록체인 기반 농생명공학을 전공으로 하고 있는 박사 연구원입니다. 관련 연구 및 업무 협업 문의는 이메일로 해주시면 감사하겠습니다.
hoofarm.tistory.com
다시 코드로 돌아와서 데이터셋 학습 없이 라벨링에 대한 기본값을 가지고 있는 Yolov8을 돌려주면 Citurs canker가 당연히 인식이 되지 않을뿐더러 Citrus 조차도 인식이 되지 않는 걸 확인할 수 있다. 다만 사과라는 결과를 나타내주는데, 정확도 상당히 높은 걸 보고 다소 놀랐다. 글쓴이가 봐도 사과 같기는 하다.
%pip install ultralytics
import ultralytics
ultralytics.checks()!yolo predict model=yolov8n.pt source='/content/canker.jpg'
이제 라벨링 한 데이터셋을 학습시켜 줘서 결과가 달리 나오는지 살펴보았다. 다만 라벨링 이미지 수를 많이 주지 않아서 학습 결과가 제대로 나오지 않을 것 같지만 일단은 결과를 살펴보았다. 사실 이미지 3개로 학습하려는 글쓴이 자체가 컴퓨터에게 너무한 거지만 결과가 궁금하기도 했다.
import torch
!unzip -q "/content/citurs_cranker.zip" -d datasets && rm /content/citurs_cranker.zip결국 이미지 부족으로 학습이 잘 이루어지지 않았다. 일단 라벨링 이미지 3장만 준 것도 문제지만 분류되는 변수가 citurs, citurs_canker 두 개로 이루어져 있다 보니까 더더욱 학습이 어렵지 않았나 싶다. 라벨링 데이터셋을 늘려준다면 문제가 없기에 추후에 추가할 필요성이 있다.


train 폴더를 살펴보면 결과에 대한 이미지를 통해 한눈에 확인이 가능하기도 하지만 그래프와 수치를 보고 분석하는 것이 가장 정확하다. 해당 포스트에서는 심플하기에 눈으로 바로 확인이 가능하지만 실제로는 그래프를 통해서 확인을 해주는 것이 가장 정확하기에 그래프와 수치를 읽는 방법도 이해하고 있어야 된다.
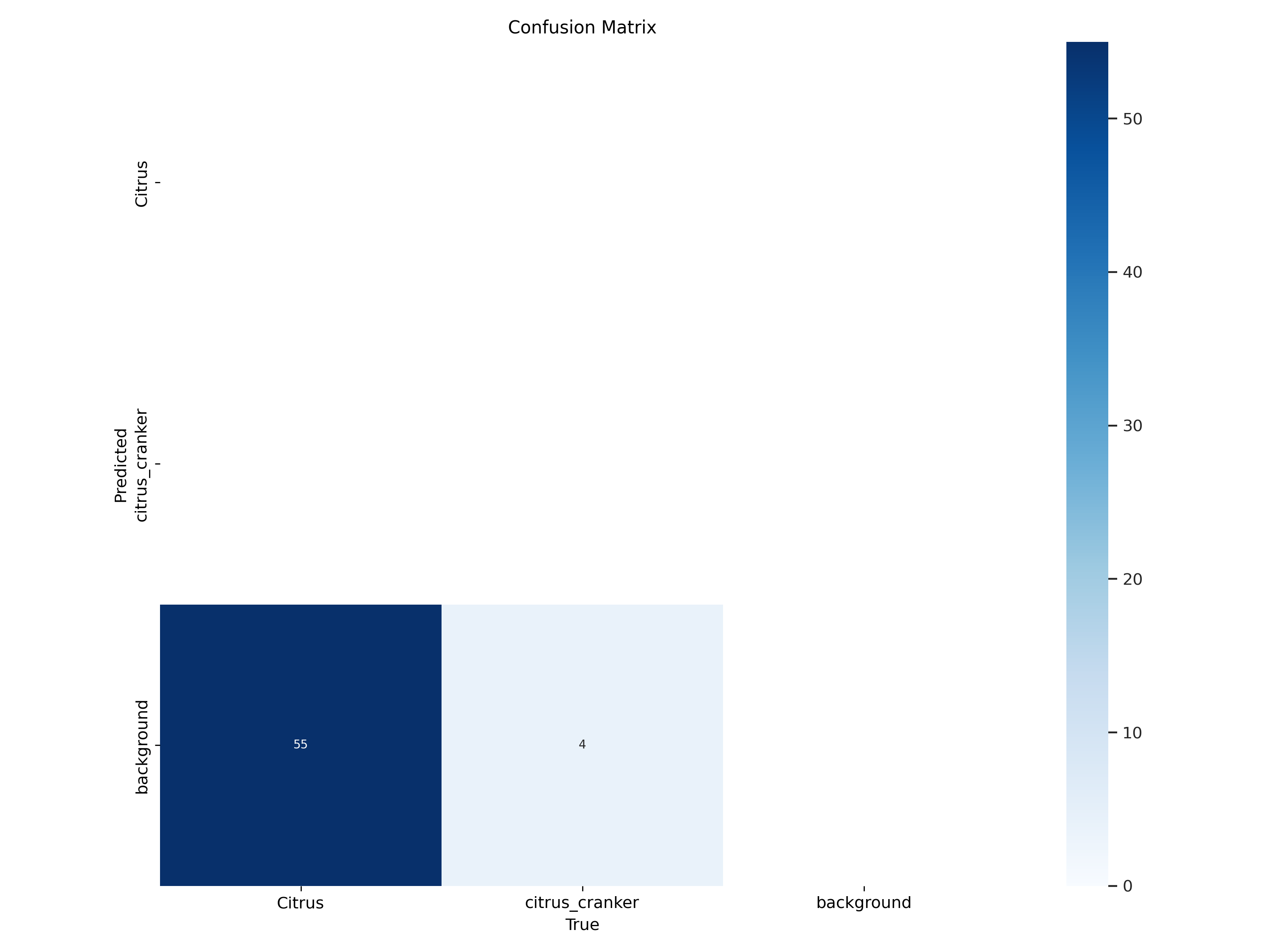
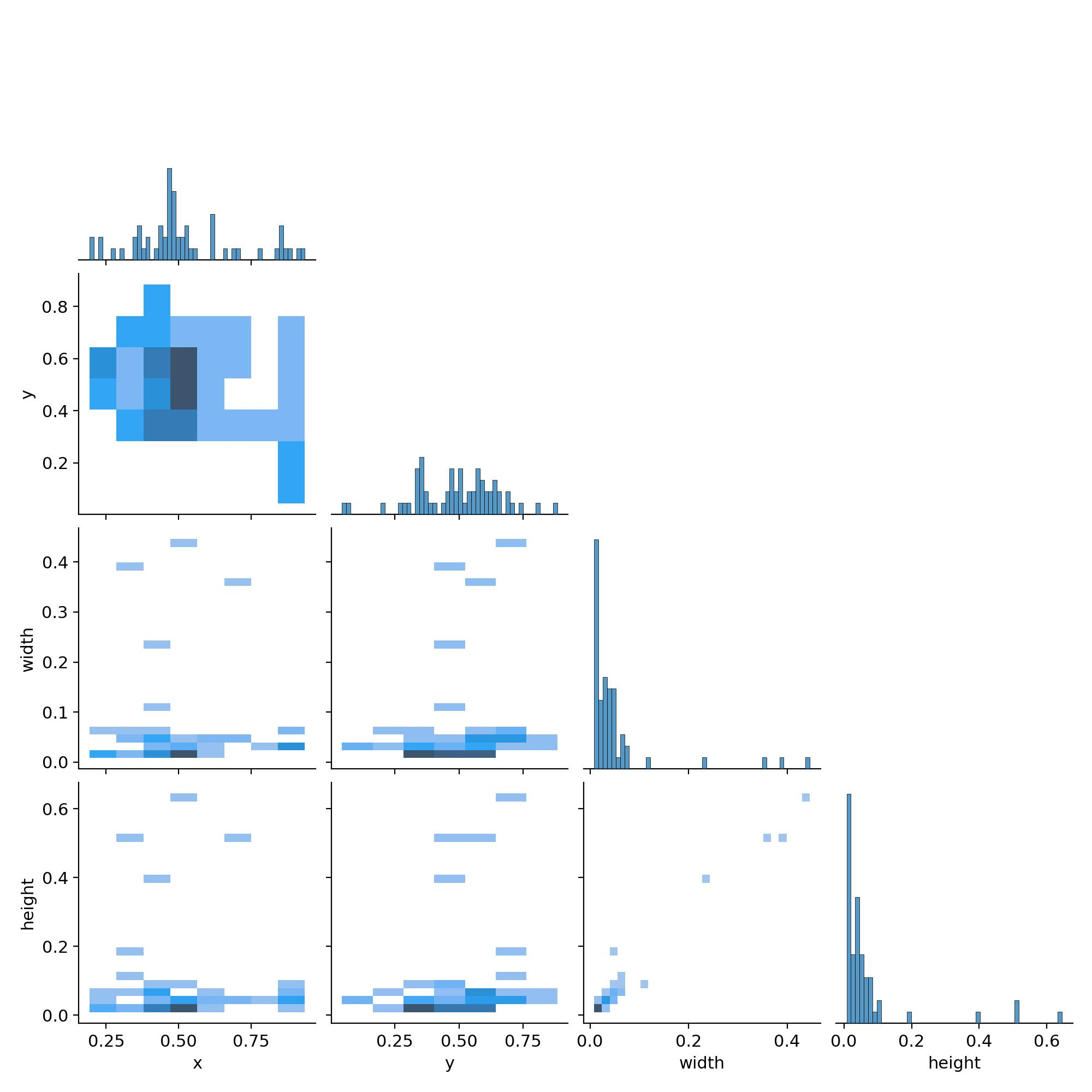
글쓴이의 경우에는 두 개의 그래프를 꼭 확인하는 편인데, confusion matrix와 labels correlogram이다. confusion matrix만 보더라도 일단 학습 자체가 제대로 이루어지지 않았음을 한눈에 파악할 수 있다. predicted 값에 표시가 되어있지 않으니 예측 값 자체가 없는 것으로 나왔다는 걸 바로 확인이 가능하다. 라벨 상관관계도 확인해 보면 워낙 학습할 데이터 수가 적으니까 거의 분산되어 있는 걸 확인할 수가 있다. 하지만 프로세스 자체에는 문제가 없으니 이미지 수가 적더라도 일단은 결과를 산출해 준다는 걸 알게 되었다. 이렇게 아주 간단한 방법으로 커스텀 데이터셋을 통한 object detection이 가능하다.
# 자료 출처
모델링 학습에 사용된 Citurs canker 이미지는 U.S. Department of Agriculture에서 제공하는 이미지를 활용하였습니다.
https://www.usda.gov/
USDA
Skip to main content USDA FAQ's and resources about coronavirus (COVID-19). Learn More Home Expanding Access to Rural Health Care USDA is expanding access to health care for more than 5 million people living in 39 states and Puerto Rico. Learn more Ou
www.usda.gov
'Computer Science > AI & Data' 카테고리의 다른 글
| [Data Science] 데이터 사이언스가 쓸모 없는 이유 (0) | 2023.08.24 |
|---|---|
| [Data Science] 경기데이터드림: 경기도 AI 학습용 공공 데이터 칭찬해요! (0) | 2023.08.23 |
| [Data Science/Colab/Jupyter] 코랩, 주피터에서 압축 푸는 방법: torch, zipfile, patool (0) | 2023.08.03 |
| [AI / Computer Vison / Object Detection] COCO Dataset으로 간단한 Object Detection 해보기 (0) | 2023.07.27 |
| [AI / Computer Vision] YOLOv8 맛보기 후기 (0) | 2023.07.27 |


댓글